
We live in an uncertain world. Uncertainty is an inherent aspect of decision making. We can reduce uncertainty, but we will never be in a state of absolute certainty. We need a way to survive in a world that is uncertain, ever-changing, and unpredictable. A world in which the unexpected can happen. A world in which Black Swans, wars, natural disasters, pandemics, and other ‘unlikely’ events are very likely to happen. We just don’t know what will happen and when it will happen, where it will happen, and how it will impact us.
Decision making is the result of applying the outcome of a (mental) model of reality to a specific situation. We need to remember the advice from Box and Draper: “Remember that all models are wrong; the practical question is: “How wrong do they have to be not to be useful?”. We always need to question a model, because models are incomplete and have a subjective interpretation of reality. They deliver us useful information that will help us make better decisions, but they continuously need to be challenged, governed, and reviewed.
A more existential reason for uncertainty is that we are generating uncertainty ourselves. Our decisions and actions, with uncertain impacts, will create uncertainty for future decisions. When we act on a decision, we influence the environment that we’re in. We decide and take action to change the reality in which we were, when we made the decision, to achieve the expected, but uncertain, outcome(s). Decisions that lead to actions change our reality. This requires us to review, and update, our (mental) model.
A more existential reason for uncertainty is that we are generating uncertainty ourselves”
One of the main causes of uncertainty in decision making is the absence of perfect information. Complete information, the assumption underlying many theories of rational decision making, does not exist. We are in a constant state of incomplete and flawed information.
There are many dynamic processes going on in our organization, in our business environment, and in the world. Constant change is the rule and not the exception. Data that was relevant and usable yesterday may not be usable tomorrow. Data about the situation last year may be relevant for some decisions while it will be irrelevant for others. We will be unable to get all the information that is needed. If we are, for example, looking at a marketing interaction, we will never have the detailed information about what the emotional state of a person reading our email, or looking at our website at a specific time. We need to accept that humans are emotional decision makers. We need to consider that there is unpredictability in their behavior.
Data is often collected from a variety of sources and may be subject to errors or inaccuracies. This can lead to uncertainty about the accuracy of the data. All the data that we’re using is also subjective. Choices have been made regarding what data to store, how to store it and more. When we collect Social Media data from the internet, it is subjective and biased because we’ll never have the opinions of all the people on Facebook or on Twitter. We will only be able to collect the data on people that are actively using these platforms and voicing their opinion. We definitely will not have data about people not on Facebook or Twitter. Therefore, we will never be perfect.
There are many dynamic processes going on in our organization, in our business environment, and in the world. This can lead to uncertainty about the accuracy of the data.”
A next source of uncertainty is the complexity of the problems organizations need to decide upon. These problems require multiple considerations and a wide range of information. There will be multiple possible decision alternatives. Or it can be impossible to decide because we have no information at all, we are too late, or there are only bad alternatives available. This complexity can make it difficult to identify the best course of action, leading to uncertainty about the final decision.
We must make our decisions in an environment that is unconfined. Our environment is a world with open, nonlinear processes or systems, with feedback, that deliver irregular or erratic behavior. And this environment has an ever-changing nature. This will lead to incomprehensibility, because we are unable to completely consider all spaghetti-like influences from ever-changing, erratic, or unknown outside events. In short, organizations will face a rapidly changing environment, such as changes in the economy, changes in markets, changes in human behavior, changes in technology, or changes in the competitive landscape. This can make it difficult to predict the future and can lead to uncertainty about the outcomes of a decision.
Our environment is a world with open, nonlinear processes or systems, with feedback, that deliver irregular or erratic behavior. This can make it difficult to predict the future and can lead to uncertainty about the outcomes of a decision.”
Finally, we have some more fundamental sources for uncertainty. Heisenberg’s uncertainty principle and the second law of thermodynamics are fundamental concepts in physics that can have a significant impact on organizational decision making. These principles can affect an organization’s ability to predict and control outcomes and can lead to uncertainty and entropy in decision making processes.
Heisenberg’s uncertainty principle, also known as the principle of indeterminacy, states that the more precisely the position of a particle is known, the less precisely its momentum can be known, and vice versa. This principle has implications for organizational decision making in that it suggests that there may be limitations in an organization’s ability to predict and control outcomes. Organizations will be uncertain about the outcome of a decision and will have to accept a degree of unpredictability in their decision making process.
The second law of thermodynamics, also known as the law of entropy, states that in any energy transfer or transformation, the total entropy of a closed system always increases over time. This principle has implications for organizational decision making in that it suggests that over time, systems tend to become more disordered and less predictable. Organizations will find that their decision making processes become less efficient and less effective over time, and may need to take steps to counteract this trend.
Data and analytics in decision making
Humans build up expectations about future values or events to make decisions. A good illustration for that is decision making in investing. Investors will assess the future values of a stocks on the stock exchange. Based on that assessment they will decide which stocks to buy. But also, more day-to-day decisions are based on future expectations. For example, where we will go on vacation depends for a large part on our expectations of the weather.
When deciding, it is crucial to understand the uncertainty associated with the expected outcomes, as this can impact the final decision that is made. In many cases, decision makers are faced with a range of potential outcomes for a given decision, some of which may be more favorable than others. Variance provides a way to understand how much the expected outcome is likely to deviate from the expected outcome, which can give decision makers a better idea of the risks and benefits associated with a particular course of action. Variance is the remaining uncertainty surrounding our expectation.
When using data in decision making, we try to reduce the variance, the uncertainty, by using additional information as input. We often rely on historical data. For example, if a company wants to decide about the launch of a new product, it may look at past sales data for similar products to determine what the likely demand for the new product will be. Similarly, if an individual wants to decide about investments, they may look at the historical performance of different investments to determine what the likely return on their investment will be.
A short history
The history of data and analytics in science and decision making spans centuries and has played a crucial role in advancing our understanding of the natural world, increasing our knowledge, developing new solutions, and informing decision making in organizations. The development of new methods for analysis and the increasing availability of data have revolutionized the field, but also pose new challenges to be addressed.
Empirical data, which refers to data collected through observation and experimentation, has played a crucial role in the history of science and decision making. The use of empirical data dates to ancient civilizations, where humans used observations of the natural world to make predictions about the future and to understand the underlying causes of natural phenomena. One of the earliest examples of the use of empirical data in science is the work of the ancient Greek philosopher Aristotle. Aristotle made extensive observations of the natural world and used this data to develop his theories on biology, physics, and other areas of science. His work laid the foundation for the scientific method.
In the Middle Ages, the use of empirical data was largely overshadowed by the influence of religious and philosophical beliefs. However, during the Renaissance, the development of innovative technologies, such as the printing press and the telescope, enabled scientists to collect and analyze data, and share results and ideas, on a larger scale. This led to the emergence of new fields of science, such as astronomy and biology, and the development of new methods for analyzing data.
In the 17th and 18th centuries, the Scientific Revolution saw the rise of a novel approach to science based on empirical data and experimentation. Scientists such as Galileo, Kepler, and Newton used data and experimentation to test their hypotheses and to develop new theories about the natural world. This approach to science, known as the scientific method, became the dominant approach to scientific inquiry.
Advances in technology in the 19th century, and the development of new fields of study, such as statistics and economics, led to the collection and analysis of data on an even larger scale. This era also saw the rise of social sciences, such as sociology, anthropology, and psychology, which relied heavily on empirical data to understand human behavior and social dynamics.
The use of empirical data in science and decision making continued to evolve in the 20th century, with the development of innovative technologies and techniques for data collection and analysis. With the advent of computers and the internet, scientists and decision-makers have been able to collect and analyze data on an unprecedented scale, leading to new insights and breakthroughs in a wide range of fields.
Also in the 20th century, the field of analysis underwent significant development with the advent of new methods for analyzing data. For example, the development of hypothesis testing, which is a method for determining whether a statistical hypothesis is probably true or false, had a major impact on the field of statistics and how data is analyzed. Additionally, the invention of electronic computers in the 1940s revolutionized data analysis by allowing for the manipulation and analysis of large datasets.
Bayesian Methods
An important development in this century was the revival of Bayesian methods. The origins of Bayesian methods can be traced back to the 18th century, when Reverend Thomas Bayes and Pierre-Simon Laplace developed the Bayes’ theorem, a mathematical formula that describes the probability of an event occurring based on prior knowledge. Bayes’ theorem laid the foundation for Bayesian statistics, which is a branch of statistics that uses Bayes’ theorem to update the probability of an event occurring as new information becomes available.
Bayesian methods are a way of making predictions and decisions based on uncertain information. They are different from traditional hypothesis testing methods, such as those developed by Fisher and Pearson, in that they use prior knowledge and probability to make predictions, rather than relying solely on data.
In the early 20th century statisticians began to develop more formal Bayesian methods. They built upon Bayes’ theorem by introducing the concept of a prior probability, which represents an initial estimate of the likelihood of an event occurring before new data is collected. This prior probability is then updated as new data becomes available, allowing the decision maker to adjust their predictions based on the latest information.
One of the key differences between Bayesian methods and traditional hypothesis testing is the way they handle uncertainty. In traditional hypothesis testing, uncertainty is often treated as an unknown parameter that must be estimated from data. In contrast, Bayesian methods embrace uncertainty and allow for the incorporation of prior knowledge and probability into the decision making process.
For example, imagine a business wants to predict the likelihood of a new product being successful. Using traditional hypothesis testing, the business would collect data on the product and use that data to estimate the probability of success. However, with Bayesian methods, the business would also incorporate prior knowledge, such as market research and customer feedback, into the decision making process. This allows for a more informed prediction that takes into account both data and prior knowledge.
Another key difference between Bayesian methods and traditional hypothesis testing is the way they handle multiple hypotheses. In traditional hypothesis testing, a null hypothesis is tested against an alternative hypothesis. The goal is to reject the null hypothesis if there is enough evidence to support the alternative. In contrast, Bayesian methods allow for the consideration of multiple hypotheses at once and assign probabilities to each hypothesis based on the available data and prior knowledge.
Bayesian methods began to gain traction in business and industry in the 60s and 70s. Today this approach is being used in wide range of fields, including risk management, finance, marketing, healthcare, meteorology, quality control, auditing, cyber security and many more. In recent years, Bayesian methods have become increasingly popular in the field of machine learning. This is because Bayesian methods provide a way to incorporate prior knowledge into machine learning algorithms, allowing them to make more accurate predictions. Additionally, Bayesian methods can be used to model complex systems and handle large amounts of data, making them well-suited for big data applications.
Recent developments
The field of data analytics has also undergone significant development in the latter part of the 20th century and in the 21st century. With the advent of computers and the internet, organizations have been able to collect and analyze data on an unprecedented scale. This has led to the development of new techniques, and the broader practical application of existing techniques, for analysis, such as machine learning and big data analytics.
Since the explosion of available data at the end of the 20th and the beginning of the 21st century and the rapid advances in computing and analytics technology, data and analytics have become increasingly important. The implementation of data, statistical methods, and machine learning has enabled organizations to make more informed decisions, improve their operations, and gain an advantage.
Data Driven Decision Making
With the increased use of empirical evidence as the basis for our understanding of the world, analytics has become the cornerstone of our decision making. Data Driven Decision making is driving innovation and improvement in science, engineering, business, and in the public sector.
Data-driven decision making (DDDM) is the process of using data and analytics to inform decisions. This approach is based on the idea that data can provide a more objective and accurate basis for decision making, as opposed to relying solely on intuition or experience. This process includes defining the decision, collecting, and preparing data, analyzing data, making the decision, and monitoring and evaluating the decision. DDDM is a powerful approach that can provide a more objective and accurate basis for decision making and can help organizations to make more effective and efficient decisions.
The process to follow in DDDM can be described with five interrelated activities:
- Defining the decision: The first step in DDDM is to clearly define the decision that needs to be made and the problem that needs to be solved. This includes identifying the objectives and goals of the decision, as well as the stakeholders who will be affected by it.
- Collecting and preparing data: The next step is to collect and prepare the data that will be used to inform the decision. This includes identifying the sources of data and the data that is needed, as well as cleaning, transforming, and integrating the data.
- Analyzing data: Once the data is prepared, it is analyzed to identify patterns, trends, and insights that can inform the decision. This includes using statistical and machine learning methods to analyze the data, as well as using data visualization tools to present the data in a clear and meaningful way.
- Making the decision: With the data and insights from the analysis, the decision can be made. This includes evaluating different options, considering the trade-offs, and making a final decision that aligns with the objectives and goals.
- Monitoring and evaluating the decision: After the decision is made, it is important to monitor and evaluate its effectiveness. This includes gathering feedback from stakeholders, tracking the results of the decision, and adjusting as needed.
OODA-Loop
These activities do not, however, describe the intricacies of the continuous learning cycle that the DDDM process relies upon. A more useful description of how people make data driven decisions can be drawn from John Boyd’s OODA loop.
Boyd describes the process of decision making as a set of interwoven activities named Observe – Orient – Decide – Act. With this OODA loop, Boyd describes how decision makers gain situational awareness by continuously iterating through a series of embedded loops.
Boyd views the process of decision making as continuously creating, adapting, and destroying mental concepts that represent patterns that we perceive in observations. We create new concepts when we observe something new. A process he links to a bottom up, or specific-to-general, discovery process that he names “creative (or constructive) induction.”
We then need to check our consistency in describing reality as we perceive it using a top down, or general-to-specific, (deductive) analysis to see if our current understanding matches perceived reality. If the match fails, we need to adapt or destroy our current mental concept and rebuild it. Boyd calls this process “deductive destruction”. This continuous cycle of creation and destruction continues until we have a consistent mental concept that matches reality. When we reach this state, it allows us to understand a part of observed reality and make decisions based on that.
Boyd warns of the danger that we can then become entangled within our own mental concept while reality might not allow for that. As he states: “we should anticipate a mismatch between phenomena observation and concept description of that observation” and we need to be willing to go through the “Create – Destroy” cycle again. His reasoning is based on three key principles in science:
- Gödel’s Incompleteness Theorem: Gödel showed that any logical system can only be shown to be consistent by using another system beyond it. Because of this our observations are also incomplete. We need to continuously refine/adapt/destroy our mental concept based on new observations.
- Heisenberg’s Uncertainty Principle: Heisenberg showed the impossibility to measure reality with certainty due to the role of the observer: “the uncertainty values not only represent the degree of intrusion by the observer upon the observed but also the degree of confusion and disorder perceived by that observer”
- Second Law of Thermodynamics: this law states that in any closed system entropy increases. Entropy describes the degree of order in a system. High entropy refers to disorder, low entropy to order.
Based on these principles Boyd concludes: “According to Gödel we cannot—in general—determine the consistency, hence the character or nature, of an abstract system within itself. “According to Heisenberg and the Second Law of Thermodynamics any attempt to do so in the real world will expose uncertainty and generate disorder.” Taken together, these three notions support the idea that any inward-oriented and continued effort to improve the match-up of concept with observed reality will only increase the degree of mismatch.” His solution for this problem is the “Dialectic Engine”: a continuous loop between destructive/deductive and creative/inductive thinking to create mental concepts that entities can use as decision models for deciding acting, monitoring, and coping with situations and environments.
Figure 1 displays the OODA-Loop. In his final drawing of this loop Boyd annotates it with two important remarks:
- “Note how orientation shapes observation, shapes decision, shapes action, and, in turn, is shaped by the feedback and other phenomena coming into our sensing or observation window.”
- “Also note how the entire ‘loop’ (not just orientation) is an ongoing many-sided implicit cross-referencing process of projection, empathy, correlation, and rejection.”
The many internal feedback loops and the additional annotations to his sketch indicate that Boyd clearly envisions decision making as a continuous learning process.
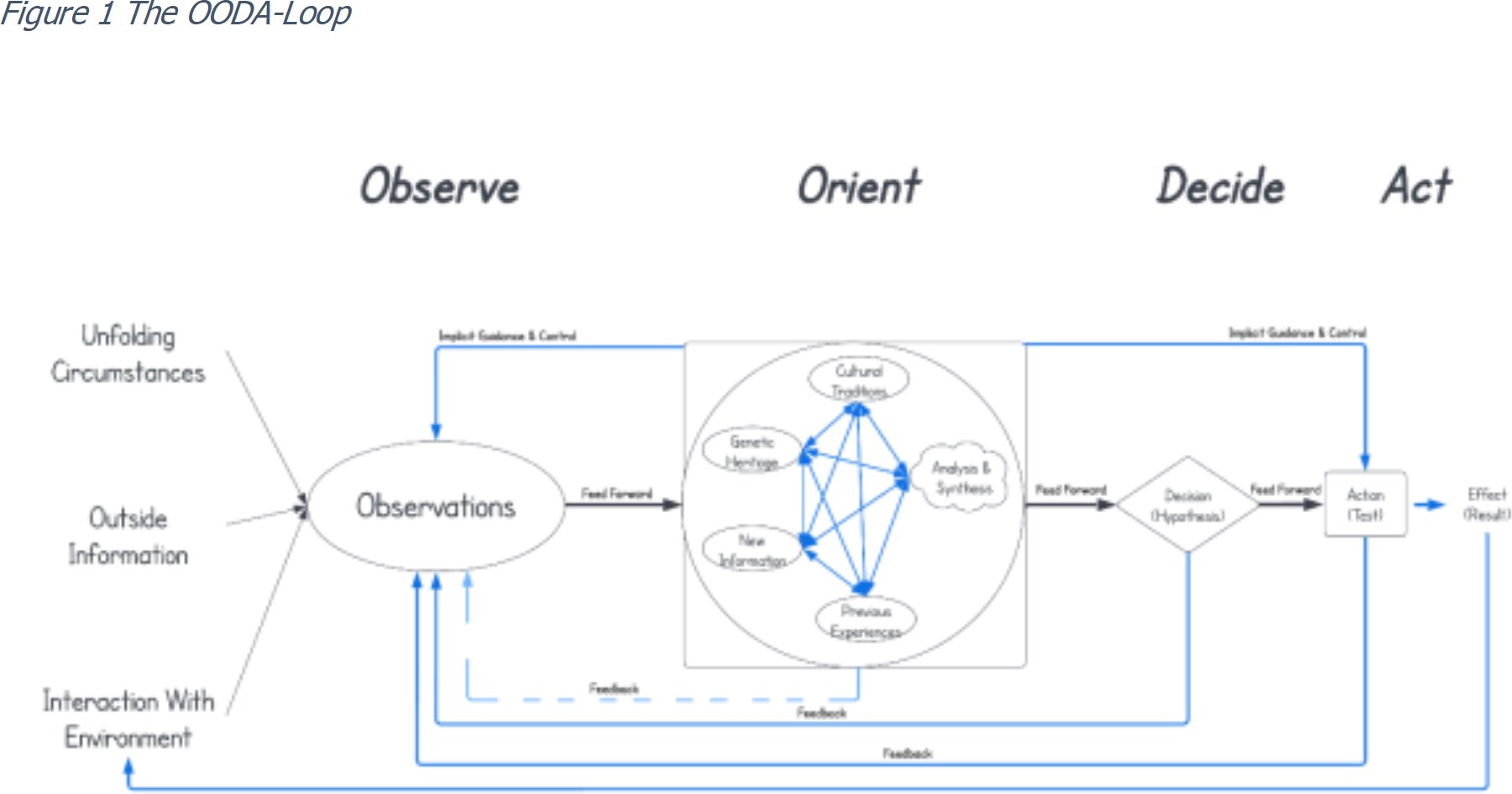
When describing the loop, it is best to start with the central activity: “Orient”. We orient ourselves with an interplay of our cultural traditions, our genetic heritage, our previous experience, and the latest information that we receive, with a process of analyzing and synthesizing to come to a new mental image of the world, that we can use to formulate a decision or a hypothesis. Again, this is not a sequential or ordered process. It is a continuous interaction between these five elements. The process is also continuously influenced by external factors like added information, interaction and discussion with others, and other feedback loops. When we orient, we shape the way we interact with the environment: how we observe, how we decide, and how we act in our present loops. These present loops, with what we learn, will shape our future orientation. It is also essential to keep in mind that it is imperative for success to foster collaboration, different points of views, and different expertise. As Boyd states: “Expose individuals, with different skills and abilities, to a variety of situations. Hereby each individual can observe and orient himself simultaneously to the others and to the variety of changing situations.”
The OODA-loop also aligns well with the ideas behind Bayesian methods. “Orient” highlights the role that prior knowledge plays in decision making. Boyd advocates the use of that prior knowledge, but he also stresses that when the evidence is against it, we need to dismiss it and start again from scratch. He was willing to do that himself according to his obituary in the proceedings of the U.S. Naval Institute: “he had a secret weapon: his uninhibited imagination was tightly coupled to a maniacal discipline to follow the truth wherever it might lead—even if it meant trashing his own creations.”
The input, that we use to orient, comes from what we “Observe”: our observations or data. These observations reflect what we have measured about unfolding circumstances, information that we get from the outside, and the data generated by our constant interaction with the environment. The observations, and especially mismatches that we identify, drive us to orient, or to re-orient. The outcome of orienting is that we have a new mental picture and are ready to decide. We formulate a decision or a hypothesis. Based on this formulation we can Act. Either by taking an action based on our decision, or to test our hypothesis. Our action has an effect. As a side note, this is a small adaptation to the original OODA-loop, that makes more explicit, that we and our decisions and actions are part of the system, and, therefore, influence and shape the system.
We see the effect return in our observations through a feedback-loop to our interactions with the environment and/or changes in unfolding circumstances, and/or outside information. This allows us to evaluate, or test, if the decision that we have taken, and the action because of that decision, has the expected result. We can now also identify possible new mismatches.
There are multiple other feedback-loops. Our decisions feedback into the observations. When we decide, we generate data. Every time we act, we generate new observations. Or we may decide that a change is needed in the observations. In that case, our action has a direct effect on what and how we observe.
An additional adaptation to the original is the feedback from orient to observe. While we are orienting, we may require additional added information from our observations. Although we could describe this as a separate OODA-loop, in which we decide that we need the latest information and act to achieve that, this is usually not as explicit. So here we depict it as a separate, dashed, feedback-loop.
So here it is: The OODA Loop. This loop also describes modern data driven decision making. We identify a mismatch or problem. We analyze the problem, and the synthesis leads us to collect data or observations. We orient ourselves using either business analysis or more advanced data science methods. We form hypotheses and test these, like, for example, early predictive or machine learning models, or new dashboards. And, finally, we use the results to act. With the goal to shape our environment, for example by implementing a recommendation engine on our website, or by using traffic density predictions to adjust our route to our destination, or by providing easy dashboards for decision makers to help them orient.
OODA-O for Organizations
Boyd already specified some key ingredients that need to be present in organizations for them to be successful decision makers. It is imperative for successful decision making to foster collaboration, different points of views, different expertise, and knowledge domains. As Boyd states: “expose individuals with different skills and abilities against a variety of situations. Hereby each individual can Observe and Orient himself simultaneously to the others, and to the variety of changing situations.”
Boyd also makes a case for leaders who are facilitators, motivators, enablers, unambiguous communicators, and inspirators. He stresses the importance of morality and ethics in decision making, too. We always, and continuously, need to evaluate and improve our moral code, and, when we live and act according to it, we need to let the world know.
The OODA loop for organizations, the OODA-O-loop (Figure 2), is very similar to that for individuals. Organizations also orient themselves on a situation using observations about unfolding circumstances in the market or their area of interest from data from external sources and definitely from the data they collect based on their interactions with the environment customer data partner data financial data transaction data, etc.
The first difference shows up in guidance and control. While for individuals this is an implicit internal process, for organizations it is more often explicit through the way of working in an organization, the way data are collected, and the way decisions and actions are taken. In organizations guidance and control usually are, therefore, more evident.
The second difference is in how organizations orient themselves. The orientation is driven by the strategy of the organization and the organizational culture. The strategy provides direction, priorities, and ethical and moral boundaries. The organizational culture sets, or removes, limitations based on the leadership style, the freedom of discussion, risk appetite, and acceptance of changes, that are needed to successfully derive optimal decisions for the organization.
These two elements also have a large influence on the third difference: in an organization we have a collection of individual OODA Loops working together. These not only influence the strategy and the culture, but, very importantly, also each other. People teach and learn from collaborators and there is a continuous process of persuading and convincing. That is why there is an additional loop back to itself.
The strategy and the culture, especially leadership style, have an important influence on how people learn from each other and create synergy in the decision making process instead of friction and opposition. A well-defined strategy helps to create insight and vision. The organizational environment needs to provide, for leaders and subordinates, the opportunities to continuously interact with and learn from the internal and external world and with and from each other in order to more quickly harmonize, design alternatives, and take coordinated initiatives needed to form an organic whole. It needs to have an implicit orientation that provides insight and vision, focus and direction adaptability and security.
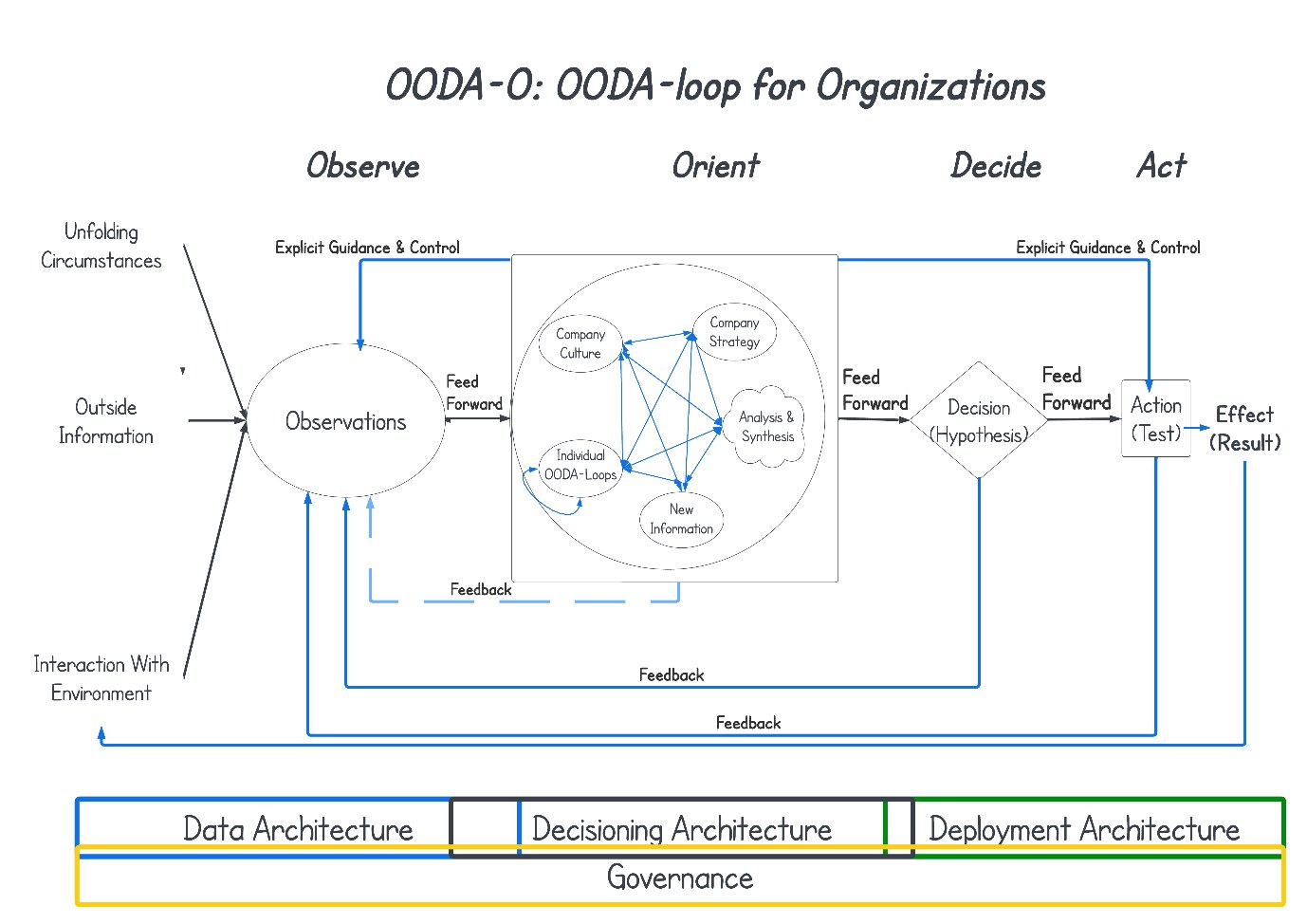
– Figure 2 The OODA-O-Loop
The environment needs to be goal and action driven. Members work together in a culture of cooperation, open communication, continuous learning, and esteem. Leadership, according to Boyd, is “the art of inspiring people to cooperate and enthusiastically take action toward the achievement of goals.” Leaders give direction in terms of what is to be done in a clear unambiguous way. Leaders are facilitators motivators, enablers, unambiguous communicators, and inspirators.
To facilitate this in an organization, the OODA-O-Loop needs to be built on a secure foundation of a Decisioning Architecture, supported by a Data Architecture, and propagated by a Deployment Architecture. An architecture, in this context, can best be described as an integrated set of processes procedures organizational structures technology and data, that is built to support a business activity, and to achieve a business objective, aligned with the business strategy. It is broader than just a technical environment. It includes all organizational aspects that help leverage, maintain, update, and manage the data-driven decision making process.
Based on this understanding of an architecture, we can describe a Data Architecture as an integrated set of processes, procedures, organizational structures, technology, and data, that support all data access and collection, data integration, data protection, data governance, data lifecycle management, and data storage activities in an organization. It is the “Observe” environment of the OODA-O-Loop.
The decision architecture contains a similar set for decision and hypothesis design and development. In this set there are processes, procedures, organizational structures, technology, and data, that focus on analyses and designing decisions and actions and developing new hypotheses. It contains technology for reporting, visualization, dashboarding, statistics, machine learning, optimization, lifecycle management, etc. It is the “Orient” environment of the OODA-O-Loop.
We need a Deployment Architecture to enable us to actually take an action or to test a hypothesis. If we don’t have processes, procedures, organizational structures, technology, and data to deploy into our business processes, we cannot derive the expected positive results. The organization will see no benefits. This is the “Decide” and “Act” environment of the OODA-O-Loop.
These three architectures need to be, and will be, overlapping and integrated. This allows for more seamless and faster decision making in action, which will lead to faster success.
Finally, all this needs to be built on top of a bed of governance. An organization will need governance to assure alignment with the strategy, the strategic objectives, the organizational ethics and morals, and the compliance with societal and legal requirements that surround data-driven decision making.
Moral, Ethical, and Legal Aspects
An organization needs to determine the balance between ethically treating customers, citizens, patients, employees, suppliers, shareholders, partners, competitors and other stakeholders and their objectives. They need to have a point of view on how to handle the environment, government regulations, ethical issues as discrimination, sustainability, human trafficking, sourcing from conflict areas, corruption and more.
The ethical and moral aspects of DDDM are essential for ensuring that an organization’s decisions align with its values and mission, and that its actions do not harm its stakeholders. Organizations have a responsibility to consider the impact of their decisions on stakeholders, ensure fairness and justice, be transparent and accountable, protect privacy and data, and consider the long-term consequences of their decisions. By addressing these ethical and moral considerations, organizations can ensure that their decisions are responsible and sustainable.
The main ethical and moral considerations in DDDM can be put in the following categories:
- Fairness and justice: Organizations have a responsibility to ensure that their decisions are fair and just, and that they do not discriminate against certain groups of people. This can include ensuring that the organization’s hiring practices are fair and that its products and services are accessible to all.
- Prevent harm: Organizations have a responsibility to ensure that their decisions do not harm their stakeholders, including employees, customers, and the community. This can include ensuring that the organization’s actions do not harm the environment or contribute to social inequalities.
- Transparency and accountability: Organizations have a responsibility to be transparent about their decision making processes and to be accountable for the consequences of their decisions. This can include being open about the data and information used in decision making and taking responsibility for any negative impacts of the decision.
- Privacy and data protection: Organizations have a responsibility to protect the personal information of their stakeholders and to ensure that data is used responsibly. This can include ensuring that data is collected, stored, and used in compliance with relevant laws and regulations.
- Long-term consequences: This can include considering the impact of a decision on future generations and on the environment. Organizations should strive to make decisions that are sustainable and that will not harm future generations.
Every decision has an ethical dimension, even when we are not aware of it”
Every decision has an ethical dimension even when we are not aware of it. Even when we decide on buying something as simple as a pack of milk. When buying a pack of milk most of us will not consider the ethics behind that decision. We will buy the cheapest, the brand we always buy, the one that happens to be available in the store we happen to be, or based on some other criterion. Others may not agree with our choice because of ethical reasons for example because they think you should only by local products, because of the carbon footprint, and the brand you have bought comes from another country. Or they may say that it is ethically not justifiable to use any animal produce. Others may have ethical issues with the store you buy the milk from because of how they treat their employees, or they may have issues with the type of packaging of the milk. For every decision there are ethical arguments pro and con.
The growth in the use of data driven algorithms has already ignited the discussion about ethical issues. ‘Unchecked’ algorithms will maintain, reinforce, and amplify existing biases, inequalities, and injustices. But there are positives as well.
Most of these discussions are based on the issue that historic data presents patterns of historic (biased, prejudiced, unfair, …) decision making that, if unchecked, will show up in the new algorithms and “survive”. People forget that the use of algorithms makes it possible to have this deeper discussion on ethics in decisioning that wasn’t possible before because all the algorithms were hidden in the brains of humans. An algorithm doesn’t have to be automated. Decision rules, or “human driven” algorithms, have been in place for years. Psychology and the former practice of knowledge elicitation in expert systems have shown that these “human driven” algorithms are very difficult, if not impossible, to make explicit. The bias in the data is for a large part the result of these “human driven” algorithms from the past. The data driven algorithms are ‘rediscovering’ what was happening. We can now see what negative side effects our historic “human driven” decision making processes had, and we can discuss them and how to prevent that in the future. Even when we do not implement an data driven algorithm, we should use the results to improve our “human driven” decision making.
The use of automated algorithms makes it possible to be more consistent in the decision making processes. In the past decision based on human judgment could turn out differently for cases that were exactly the same. Human decision making can be influenced by so many factors (the weather, mood, the way you look, …) that there was no consistency in judging all cases against the same criteria. The use of automated algorithms can remove that inequality and provide consistency.
The positive effect of this discussion is the pressure to use higher quality data. Better quality data brings an improvement in the way we make decisions. We tend to forget that in the past decisions were made on even worse data.
When using data driven algorithms transparency and auditability are built in. Most automated algorithms are developed with a clear process that is built around scientific data analysis approaches. This leads to algorithms that are based on a process of critical thinking, testing & validation where in the past the decision rules were often based on assumptions, prejudices, biases (in decision making & and in the limited analyses that were done at best).
But there are some negatives as well that we need to consider. Implementing algorithms introduces unique additional biases.
When evaluating algorithms, we need to be aware that algorithms are not neutral. They are always defined with a goal in mind and goals are based on assumptions, priorities, and emotions. Choices have been made in building the algorithm, the techniques employed, the design and programming, the translation of the technical output to a decision. Finally, you might have rogue algorithms: algorithms that have errors in them, because they’re not developed correctly, or that are using data that you do not want, and that, because of that, might have an effect that you do not want.
Our actions, based on the algorithm, influence the outcome. We need to be very much aware of the limited time a version of the algorithm may be used. We may need to take our actions into account in our algorithm. When acting on an algorithm’s prediction we either take an action to prevent it from happening, ensure its stability, or increase the likelihood that it will happen. We are changing the reality the original algorithm was based upon.
A major issue is the subjectivity of data and the ethical boundaries of data collection and usage. A business has also to decide what their ethical boundaries are in collecting and using data. Does profit/growth/shareholder value/market capitalization/ justify everything?
Most scientist have learned and some have remembered: the context of data is always relevant. Data cannot manifest the kind of perfect objectivity and quality that is sometimes imagined. Any data we create and collect are a result of the theory we hold of reality, the choices we make and the priorities we have, the technology and the sources we use. We will also need to accept that we will never have all data. No matter what big data marketing says: deciding based on complete and perfect information will remain a non-starter.
Laws & Regulations
Laws and regulations play a critical role in shaping the ethical and moral aspects of organizational decision making. In Europe, the USA, and the rest of the world, there are a variety of laws and regulations that address ethical and moral considerations, and more are on the drawing board, like “The AI Act”. Both the EU and in the USA are working on their own versions. Organizations have a responsibility to comply with these laws and regulations, and to take into account the interests of stakeholders in their decision making. By doing so, organizations can ensure that their decisions are responsible and sustainable.
In Europe, the General Data Protection Regulation (GDPR) is a key regulation. The GDPR sets out strict rules for the collection, storage, and use of personal data, and requires organizations to obtain explicit consent from individuals before collecting their data. The GDPR also requires organizations to appoint a Data Protection Officer (DPO) to ensure compliance with the regulation.
Another key regulation in Europe is the Corporate Social Responsibility (CSR) Directive. The CSR Directive requires organizations to report on their social and environmental impacts, and to take into account the interests of stakeholders in their decision making.
At the moment of writing, the EU is in the process of creating a new regulation, called “The AI Act”. This regulation will ban certain types of technology applications and highly regulate some others, that are considered high risk. The high-risk applications are mostly applications that can negatively affect the life and rights of human individuals.
In the rest of the world, there are a variety of laws and regulations that address ethical and moral considerations in organizational decision making. For example, the United Nations Global Compact is a voluntary initiative that encourages organizations to adopt sustainable and socially responsible policies and practices.
In addition, many countries have laws and regulations that prohibit discrimination, ensure fair labor practices, and protect the environment.
To comply with these laws and regulations, organizations must establish policies and procedures to ensure compliance. These can include:
- Appoint a compliance officer, or even an ethics officer.
- Establish codes of conduct.
- Establish ethics committees.
- Provide training to employees on ethical & compliance issues.
- Establish processes to evaluate the ethical and moral implications.
- Include stakeholders in the decision making process and consider their interests in decision making.
- Implement robust cybersecurity measures to protect the sensitive information of their stakeholders, their own reputation and the trust of their stakeholders, their own financial and intellectual property.
- Conducting regular audits to identify and address any issues.
Improving human driven decision making
DDDM has the potential to prevent errors in human-based decision making with its psychological flaws. Human decision making is often influenced by cognitive biases, emotions, and other factors that can lead to inaccurate or irrational decisions. DDDM, on the other hand, relies on data and analytics to inform decisions, which can provide a more objective and accurate basis for decision making.
One of the main psychological flaws that DDDM can help prevent is confirmation bias. Confirmation bias is the tendency for people to seek out and interpret information in a way that confirms their existing beliefs and hypotheses. DDDM, on the other hand, relies on data and analytics to inform decisions, which can provide a more objective and accurate view of the situation. In short, it prevents tunnel-vision.
Another psychological flaw that DDDM can help prevent is the availability heuristic. The availability heuristic is the tendency for people to rely on information that is easily available or salient, rather than on information that is more accurate or relevant. DDDM, on the other hand, relies on data and analytics to inform decisions, which can provide a more comprehensive view of the situation. In short, it prevents impulsive, riskier, decision making.
Additionally, DDDM can also help prevent the sunk cost fallacy, which is the tendency for people to continue to invest in a decision or project because of the resources that have already been invested, even when the decision or project is unlikely to be successful. DDDM can help to prevent this by providing data and analytics to inform decisions, which can help organizations to make more informed decisions and to avoid investing resources in projects that are unlikely to be successful.
Furthermore, DDDM can also help prevent hindsight bias, which is the tendency of people to overestimate their ability to predict outcomes after they have occurred. DDDM provides data and analytics to inform decisions, which can help organizations to understand the factors that contributed to the outcome.
Lastly, DDDM can also help prevent the optimism bias, which is the tendency for people to overestimate the likelihood of positive outcomes and to underestimate the likelihood of negative outcomes. DDDM can help organizations to understand the potential risks and benefits of different options. It helps open “Happy Eyes & Ears.”
Challenges
Implementing DDDM in an organization can be a complex and challenging process, with potential pitfalls and mistakes that organizations should be aware of.
The main barrier is usually the culture change needed. DDDM requires a culture of data-driven decision making to be in place. This may be difficult to achieve if (executive) management and stakeholders are not on board. Implementing data-driven decision making in organizations can be met with objections and resistance from employees and managers. Some of the common reasons for this include a lack of understanding or knowledge about data-driven decision making, a lack of trust in the data or the decision making process, and a lack of resources or support.
The technical challenges are data quality and data access. Data quality refers to the accuracy, completeness, consistency, and timeliness of data. Poor data quality can lead to incorrect or unreliable insights, which can lead to poor decision making. Data access refers to the existence of data silos, data sources that are not integrated or easily accessible. Data silos can lead to a lack of visibility into the organization’s data.
Another challenge in implementing DDDM is a lack of data literacy. Data literacy refers to the ability to understand and use data to make informed decisions. Without data literacy, decision-makers may not be able to understand or use the insights generated from data.
Because a lot of organizations have ‘silo-ed’ their data processes in the ICT department, a major challenge in implementing DDDM is a lack of understanding of the problem. DDDM requires a deep understanding of the problems that the organization is trying to solve. Without a clear understanding of the problem, organizations may not be able to collect the right data or to use the insights generated from data to make informed decisions. The inclusion of subject matter expertise or domain knowledge is paramount to success.
Subject matter/Domain expertise
The process of data-driven decision making is not as simple as collecting data and running analysis. One of the key aspects of data-driven decision making is the importance of domain knowledge, which refers to the understanding of the specific industry, market, or problem that the data is being used to address.
Domain knowledge (or subject matter expertise) is a crucial aspect of data-driven decision making. Without domain knowledge, the data and analysis may be of little value, as it can be difficult to interpret the results and make meaningful decisions. By incorporating domain knowledge into the data-driven decision making process, organizations can gain a deeper understanding of the data, identify patterns and trends, and make better decisions based on the findings. Additionally, monitoring and updating the analysis as the problem evolves will ensure that the insights gained from the data are relevant and actionable.
The main reason in incorporating domain knowledge into data-driven decision making is to clearly define the problem that the data is being used to address. This includes understanding the goals of the analysis, the key questions that need to be answered, and the specific business context in which the data will be used.
The second important reason is that domain knowledge allows analysts and decision makers to understand the context of the data and to identify patterns and trends that may not be immediately apparent. Additionally, domain knowledge can also be used to identify sources of data and potential biases or errors in the data, which can affect the accuracy of the analysis and the validity of the conclusions. Incorporating domain knowledge into DDDM requires a good understanding of both the data and the business context.
After the data has been collected and prepared, domain knowledge can be applied to the analysis, too. This includes using domain expertise to identify key variables and trends in the data, to interpret the results of the analysis, and to make decisions based on the findings. After the analysis has been completed, the results must be interpreted and communicated to decision makers and stakeholders. This includes explaining the findings in a clear and concise manner, highlighting the key insights, and providing recommendations for action.
The final activities, which require domain knowledge, are to monitor the results and update the analysis, as necessary. This includes monitoring the performance of the models, updating the data, and testing new hypotheses as the problem evolves.